Как проверить сколько запросов было по слову. Статистика поисковых запросов Яндекс: описание сервиса
Очень важно убедиться, что запросы, по которым вы собрались продвигаться, вообще кто-то ищет. Если вы наберете «семантическое ядро», где все ключи будут с нулевой частотностью — то ваш сайт и будет нулём. Поэтому давайте не будем вола нагибать, а приступим.
Что такое частота ключевого слова
Очевидно, что различные запросы имеют разную популярность среди пользователей поисковых систем. Число ввода конкретного запроса в поисковик берется за один месяц. Таким образом, частота ключевых слов — это количество вводов запросов за месяц.
Вполне возможно, что даже тут есть запросы-пустышки
Для продвижения вашего сайта необходимо создавать оригинальный контент. Например, если вы пишете статьи, уникальность вашего текста должна быть, как правило, выше 90%. В теории, уникальный контент приносит высокий показатель посещаемости, состоящий в большей мере из переходов с Яндекса и Гугла. Однако в реальных условиях ранжирования написать уникальную статью — только половина успеха.
Поисковые системы обращают внимание не только на уникальность текста, но и на содержания в нем ключевых запросов, соответствующих тематике статьи или любого другого текстового контента. Правильное распределение ключевых слов в статье называют текстовой оптимизацией. Уникальная, но не оптимизированная статья, содержащие неопределенные запросы, может и вовсе не привлечь на сайт посетителей. Такая ситуация будет означать зря потраченные время и ресурсы на создание контента.
Для оптимизаторов, частотность это критерий по выбору того или иного запроса для его использования в тексте. В зависимости от частотности, на высокочастотные (ВЧ), среднечастотные (СЧ) и низкочастотные (НЧ) запросы. При оптимизации статьи, в первую очередь, обращают внимание на ВЧ и СЧ запросы. Однако с каждым годом продвижение новых сайтов становится все затруднительным, а оптимизация все тоньше. Сейчас считается, что использование НЧ ключей также может принести некоторый объем трафика.
Как проверить частотность запроса
Частотность ключевых слов можно узнать с помощью соответствующих сервисов поисковых систем, а также специальных программ по составлению семантического ядра. Поисковики предоставляют свои сервисы с расчетом подбора запросов для контекстной рекламы.
Wordstat (Яндекс)
Wordstat — cервис Яндекса по определению статистики ключевых запросов. Вордстат использует большинство оптимизаторов не только в целях составления коммерческих запросов под рекламу, но и для добычи ключевых слов в рамках обычной текстовой оптимизации. У Вордстата выделяют три вида частотностей:
- Частотность WS — базовая частотность запроса в Вордстате.
- Частотность «» WS — частотность по точному вводу запроса. Например, статистика по запросу [«автомобиль»] будет соответствовать запросу [автомобиль] без добавлений других слов.
- Частотность «!» WS — частотность по точному вводу каждого слова в запросе, исключая склонения и т.п. Запрос [!китайский] означает, что будет выдана статистика по слову [китайский] без возможных склонений (китайская, китайское).
По запросу [автомобиль] текущая частотность превышает десять миллионов показов. Однако базовый показатель предполагает добавление всевозможных слов к ключевому слову, по которым будет ранжироваться статья.

Если заключить запрос в кавычки, то статистика сократится с десяти миллионов до 28 тысяч. Для оптимизатора может оказаться полезной правая колонка с похожими запросами, которые дополняют семантический сбор.

Вкладка «По словам» означает, что статистика приводится по общей сумме показов введенного запроса. На вкладке «по регионам» отображается статистика показов в разных регионах страны. А на «Истории запросов» можно отследить по графике изменение частотности запроса в течении месяца или недели, а также статистику по по запросам через ПК или мобильные устройства.
Сервис Google AdWords сам по себе более заточен под контекстную рекламу, нежели Вордстат. В разделе «Инструменты» можно подобрать необходимые ключи под нужный запрос. В колонке «Таргетинг» задается нужный регион показов и язык. Также можно указывать минус-слова.

В отличии от Вордстата, где указывается статистика за месяц, в AdWords можно выбирать месячный диапазон показов в колонке «Диапазон дат». Недостатком является усредненный число результатов. Сама статистика разделена на два блока:
- Ключевые слова — аналог частотности «» Вордстата;
- Ключевые слова (по релевантности) — аналог базовой частотности и похожих запросов WS.

Плюсами являются присутствие уровня конкурентности, а также возможность скачать подобранные слова в CSV-файл или на Гугл Диск.
Помимо AdWords, Гугл имеет еще один инструмент по анализу запросов под названием Google Trends . Данный сервис оценивает популярность введенного запроса на определенный период времени и представляет статистику в виде графика. Можно сравнивать несколько ключевых запросов между собой. Также отображается статистика по регионам.

Для графика используются не точные числа, а относительные, основанные в том числе на релевантных запросах.
Mail.ru
Mail.ru также имеет в сервисе для вебмастеров инструмент по статистике поисковых запросов. Помимо общих показов, в таблице представлены распределение запросов по полу и возрасту пользователей.

Не секрет, что Mail сотрудничает с Яндексом, так как поисковик размещает рекламу Яндекса.
Rambler
Rambler с каждым годом теряет свою популярность, однако их Wordstat может оказаться весьма полезным. Дело в том, что статистика запросов в Яндексе и Гугле не всегда может отображать реальное положение вещей. Многие компании могут вводить «в холостую» коммерческие запросы в целях слежки за конкурентами, т.е. для анализа ТОПа, тайтлов и т.д.

По причине низкой популярности Рамблера, статистика их Вордстата обладает меньшей заспамленностью и может внести некоторую ясность для оптимизаторов. В общем, в качестве дополнительного инструмента вполне сгодится.
Как проверить массово частотность запросов
Большинство оптимизаторов выбирают для сбора и анализа семантического ядра такие программы, как Key Collector или Slovoeb. Также существуют онлайн-сервисы по определению частотностей.
Key Collector
Получить необходимые ключи для семантического ядра и массово проверить их частотность можно при помощи десктопной программы Key Collector . Открываем Вордстат, в поле заносим основные ключи с новой строки по вашей тематике и нажимаем «Начать сбор».

В настройках можно задавать требуемый регион для сбора, а также стоп-слова. После того как ключи соберутся, определяем частотности через Директ.

В итоге у вас будет таблица с ключами и частотой показов. Сразу удаляем все ключи, у которых точная частотность «!» равна нулю. Для этого делаем фильтрацию в колонке «Частотность!». Кликаем на синюю иконку. Появится окно с фильтром. Выбираем «больше или равно» > «1» и жмем «Применить».

Для получения большего списка ключей можно собрать поисковые подсказки с Яндекса. Делаем новую группу (окно справа).
Также убедитесь, что включена галка «Собирать только ТОП подсказок без перебора…». Теперь кликаем на созданную группу – откроется новая пустая вкладка. Жмем иконку сбора поисковых подсказок.
После сбора фраз делаем то же самое, что и при парсинге Вордстата: снимаем частотности, убираем неподходящие по смыслу фразы и фразы, где частотность «!» равна нулю.
Аналогично с помощью Key Collector можно собрать ключи и частотности с Гугла.
Rush Analytics
Сервис Rush Analytics является онлайн-альтернативой Key Collector. Плюсом инструмента по сбору ключей является отсутствие необходимости использовать прокси, антикапчу и т.п.
Для сбора частотности с Вордстата, необходимо перейти на вкладку «Сбор частотности» и поставить галочку напротив !ключевое слово , то есть точной частотности. Далее заносим ключевые слова. После того, как сервис посчитает затраты, нажимаем «Создать новый проект».
Результаты можно сохранить в Excel-файл.
Привет, пацаны! Все вы прекрасно знаете, что я уже давно барыжу ключевыми словами. В смысле, давно уже занимаюсь этим на коммерческой основе.
Все те свои услуги, которые я описал , уже давно были мною многократно расширены. Обращаются разные извращенцы, которые придумывают такие задания, что я бы раньше и подумать не мог. Ну и я постепенно матерею за счет того, что они вынуждают меня выполнять их сложные задания
Наверно, все помнят, что я много раз писал про базы пастухова: давным давно я рассказал, что представляет собой этот офигительный софт — , потом рассказал о том, что Максим Пастухова (автор софта) анонсировал выход 180-миллионной русской базы ключевых слов. Это .
Но вот недавно я делал проект для сайта одного солидного человека. Проект был исключительно под Яндекс. Я отпарсил его сайт, нашел ключи, по которым он уже занимает нормальные позиции в выдаче, оценил эти ключи с помощью вордстата, рамблера, Rookee… все, на этом тормозим.
В итоге получается список хороших ключей. Но! Из них получается много неоднозначных ключей. Вот они

То есть, берем к примеру ключ «радио радио слушать онлайн ». Смотрим частотность по wordstat. Здесь на скриншоте указана точная частотность. То есть, использовался оператор «!слово!слово». И что же видим? Что этот кей имеет частотность 563141 для моего региона, для которого делался анализ.
Меня клиент сразу спрашивает: «Сергей, что за херня? Откуда у несчастного «радио радио слушать онлайн » 563141 показов в месяц?» И прогноз переходов Rookee показывает -1 переход по этому ключику, что означает, что хз, сколько этих переходов будет. То есть, это говорит о том, что их будет 0.
И я потом только допер, что епта, ведь это отличная идея для поста – расписать эту залепу, которая есть в вордстате, тем более, что и Маул недавно про это писал. Только я расскажу про это со своей колокольни, и еще покажу вдобавок, как эта проблема решается.
А что залепа, то залепа. Вот как понять, что это такое на самом деле? Первое, что приходим на ум – пойти в хелп самого Вордстата, да почитать, что они сами об этом пишут. Но нет, единственное, что видим:
И что в итоге? А ничего! Из того что здесь написано, ни фига не понятно, почему мля по запросу «радио радио слушать онлайн » такое большое количество показов.
А на самом деле эта залепа имеет простое объяснение. Открываем свеженькие базы пастухова на 180 млн. кеев, делаем выборку из базы по ключевому слову «радио слушать онлайн»

Думаю, те, кто часто копаются в вордстате, прекрасно понимают, что выдернуть оттуда такие вот ключевые слова — это почти нереально.
Это, кстати, не самые длинные ключевые слова. В базах пастухова я добавил отображение частотности по wordstat.yandex. Смотрите, есть и покруче, вернее, подлиннее ключики

Или вот еще
Понятно, 10-ти словник «интернет радио онлайн слушать бесплатно европа плюс mediaplayer classic » не может иметь частотности, а если и может, то она настолько ничтожная, что не отображается в wordstat. Но дело в том, что вот такие вот многословники и создают эту залепу с ключевыми словами. Смотрите сами

Что здесь видим? Видим, что десятисловник » имеет частоту 5967, что само по себе представляется какой-то утопией.
Так почему же так получается?
Есть одна особенность в вордстате – в нем похер порядок ключевых слов, в связи с чем если не понимаешь всего этого механизма, то можно тупо просаживать баблос, двигая в перспективе ключевые слова, не дающие на выходе трафа.
Все это очень хорошо видно, когда в базах пастухова добавляем колонку со статистикой запросов в Рамблер, в котором порядок слов не похер . Тогда картина становится сразу ясна, и мы видим, для каких запросов есть система, а для каких нет. То есть, какие запросы вводят регулярно, какие действительно можно продвигать, а какие просто создают статистику для таких вот залеп, которые я показал выше. Здесь в базах пастухова особенно зашибенно то, что можно сразу прикинуть частотности Яндекса и Рамблера по отдельно взятому ключевику

Я здесь специально сгруппировал запросы, чтобы было понятно. То есть, в идеале, если продвигать, то брать такие ключи, где будет частота и по Рамблеру и по Яндексу. Но это в идеале.
И все же, как так, что 10-ти словный запрос с повторяющимися словами может иметь частоту 5967?
Я хз если честно, почему в хелпе вордстата не расписали, почему же такое вот может быть. Но суть вот в чем.
Как уже писал выше, в Яндексе вводят множество запросов, среди которых много и десятисловных. И даже больше. Из вордстата эту информацию часто не вытянуть, зато хорошо все эти ключи показывают базы пастухова (примечание — теперь уже закрытый проект). А сама разгадка кроется в том, что дублирующиеся слова не учитываются непосредственно в запросе.
То есть, запрос «!радио!радио!радио!радио!радио!радио!радио!радио!слушать!онлайн », имеющий частоту 5967, на самом деле в точно таком же виде не показывается столько, сколько это отображает вордстат. Здесь учитывается только словосочетание «радио слушать онлайн». То есть, последние три слова. А вместо предыдущих 7 слов «радио» могут употребляться абсолютно разные слова. И все это создает статистику для вот этого десятисловника. Я специально в базах пастухова сделал выборку полученных результатов по «радио слушать онлайн». Там можно сортировать и по длине поисковых запросов, и по количеству слов

И в итоге мы получаем все (или почти все) ключевые слова-десятисловники, которые и делают статистику для нашего «!радио!радио!радио!радио!радио!радио!радио!радио!слушать!онлайн ». Вот они:

И таких десятисловников более чем предостаточно. То есть, еще раз повторяюсь, что вместо слова «радио» может быть любое другое слово, лишь бы оно входило в десятисловник, который содержит словосочетание «радио слушать онлайн».
Ситуация не была бы настолько неоднозначной, если бы вордстат показывал ключевые слова в точно таком же порядке, как они запрашиваются. Но ведь нет. В нашем десятисловнике вместо слова «радио» могут быть любые другие слова, и все они могут меняться местами внутри этого десятисловника, тем самым накручивая его показатель в вордстате.
Вот поэтому и получается, что запрос «радио радио слушать онлайн » на самом деле в точно такой же последовательности и с точно такими же словами, как здесь указано, не имеет частоту 563141 и никогда не имел. А такая цифра получается, потому что вместо первого слова «радио» может быть любое другое, и может оно стоять на любом месте в рамках этого четырехсловника, что и образует в конечном итоге такую большую цифру в 563141. И таких четырехсловников разной интерпретации превеликое множество
Поводом для написания новой статьи о самом популярном инструменте для подбора слов послужило его недавнее глобальное обновление, которое привело к ряду новшеств и улучшению. Помимо небольшого рассказа на эту тему, я подробно остановлюсь на правильном использовании операторов Вордстата и других фишках сервиса.
Как узнать количество запросов в Яндексе?
Для начала небольшая справка, Яндекс Вордстат (wordstat.yandex.ru) – это инструмент для подбора ключевых слов на основе запросов пользователей, который отображает статистику по частоте использования указанного слова (первый столбец), а также, по словам из схожей тематики (второй столбец). С помощью Вордстата количество запросов в Яндексе узнают, как рекламодатели, так и SEO-специалисты.

Принцип работы заключается в том, что вы указываете слово или фразу по которой интересует статистика. Далее система показывает все ключевые фразы, в которых употребляется указанное вами слово, а рядом располагается его частотность. Каждая из последующих фраз агрегирует информацию. Минимальная частотность составляет 3.
Информация обновляется раз в месяц. Дата обновления указана в правом верхнем углу.
Новый Яндекс Вордстат. Обновление от 07.08.13
Если ранее вы использовали Wordstat для проверки запросов в Яндексе, то наверняка сталкивались с дикими проблемами в скорости работы интерфейса. Думаю, что по этому поводу было написано множество жалоб в службу поддержки. В новой версии изменилось не только это:
- Увеличена скорость работы сервиса – по моим ощущениям сервис стал быстрее в несколько раз.
- Изменена архитектура сервиса – раньше при использовании сервиса менялся URL и можно было в один клик перейти к 20-й странице, заменив один из параметров. Сейчас такая возможность отсутствует.
- Пересмотрены отдельные части интерфейса – сводная таблица по регионам объединена с данными на карте, а статистика запросов Яндекс по месяцам и неделям сгруппирована на одной вкладке.
Об автоматических программах парсерах Wordstat

Как говорится, в каждой бочке меда есть ложка дегтя. И в этот раз ложкой дегтя стал полный запрет доступа к интерфейсу проверки ключевых фраз сторонними программами, которые очень популярны у специалистов по контексту и SEO. Все мы искренне надеемся, что наши любимые сервисы как можно скорее восстановят свою работу. Здесь я привожу сводную таблицу, в которой отражены данные для популярных парсеров Wordstat по состоянию на текущий момент. Информация будет обновляться по мере восстановления работы сервисов.
| Название сервиса | Статус |
|---|---|
| Словоеб | Работает |
| Магадан | Работает |
| SiteAuditor | Не работает |
| KeyCollector | Работает |
Как пользоваться Вордстатом?
Большинство людей допускают ошибки при использовании сервиса, в следствие чего в статистике фигурируют неверные данные, а дальнейшие действия по или продвижению в поисковых системах полностью бессмыслены. Помимо этого, часто встречается искусственная накрутка количества запросов для ключевых слов. Ниже я собрал основные рекомендации по работе с Вордстатом с подробными комментариями, которые пригодятся как новичкам, так и профи:
Уточняйте фразы, используя операторы
Операторы для Яндекс Вордстата такие же, как и в Яндекс Директе. Подробнее о них — я рассказывал в статье « «. Основные операторы:
| Оператор | Комментарий | Пример |
|---|---|---|
| < — > Знак минус | Частота запроса без учета | Купить мопед –бу –москва |
| < «» > Двойные кавычки | Статистику слова или фразы по фразовому соответствию | «стоимость модем» |
| < ! > Восклицательный знак | Частотность по заданной словоформе | !ваза цена |
| < + > Знак плюс | Принудительный учет предлогов | +как работает яндекс директ |
| <(|)> Круглые скобки и прямой слеш | Группирует статистику по запросам | Кондиционер (авто | машина) |
Если первые четыре оператора популярны, поскольку они очень часто используются в Директе, то пятым практически никто не пользуется. Хотя в умелых руках он приносит пользы больше остальных, а скорость подбора слов с ним возрастает в разы. Приведу пример: для того чтобы собрать статистику для рекламы магазина галстуков-бабочек, можно использовать следующий запрос:

В результате мы получим информацию одновременно о таких запросах, как:
- заказать мужскую бабочку;
- галстук бабочка цена;
- сколько стоит женская бабочка и т.д.
Таким образом с помощью оператора группировки статистика собирается в один клик. Спектр применения достаточно широк, например, в приведенном образце можно проверить частотность для транзакционных ключевых фраз.
Подбирайте ключевые слова правильно

Не забывайте указывать регион для проверки частотности запросов и не заостряйте внимания на частотности слов по широкому соответствию, т.е. без использования операторов. Посмотрите на колоссальную разницу:
- Купить интернет магазин — 811 430
- «Купить!интернет!магазин» – 1 362
Когда вы подбираете ключевые слова для сайта, то каждое слово необходимо дополнительно уточнять, для проверки частотности по точному соответствию, поскольку очень часто встречаются фразы – пустышки.
Анализируйте статистику запросов по месяцам

Используя вкладку «История запроса» можно оценить сезонность спроса, а также посмотреть его динамику в зависимости от времени года. Также статистика по месяцам помогает с высокой долей вероятности определить натуральность частотности слова. Не вооруженным взглядом будет заметен резкий скачок графика у слов с искусственной накруткой, количество низкочастотников при этом останется на одинаковом уровне.
Используйте автоматический подбор слов (программы — парсеры)
Автоматические сервисы для подбора ключевых слов я перечислил выше. Их использование позволяет в разы сократить количество монотонной работы и время на проверку частотности с операторами и без. В ближайшее время опубликую статью о своей любимой программе для Wordstat`a – Словоеб. Чтобы не пропустить выход статьи, рекомендую подписать на обновления моего !
С уважением, Александр Golfstream!
Начинающие оптимизаторы часто задают вопросы, касающиеся частотности запросов. Что означает СЧ, НЧ И ВЧ? Возможно ли влияние тематики сайта на причисление запросов к какому либо из интервалов? И тому подобное. В этой статье я попутаюсь дать исчерпывающие ответы на данные вопросы.
Что такое частотность запросов
Разные запросы пользуются разной популярностью среди пользоваетелей интернета. Некоторые запросы задаются поисковым системам всего несколько раз в месяц, а другие несколько тысяц или даже десятков тысяч. Чем чаще используется данный запрос, тем выше его частотность.
Как узнать частотность запроса
Для того, чтобы узнать частотность того или иного запроса, можно воспользоваться несколькими специальными сервисами.
Частоту запросов в Яндексе можно узнать в wordstat.yandex.ru . Для этого, вписываем интересующее нас ключевое слово в поисковую строку и нажимаем кнопку «Подобрать». Яндекс покажет сколько раз пользователи задавали запросы, в которых встречаются указанные Вами слова.
Как видите, для запроса поисквая система это 365398 показов в месяц. Довольно внушительная цифра. Тем не менее, как уже было сказано выше, это сумма все запросов, содержащих данные слова. Для того, чтобы узнать, сколько раз запрос задавался именно в определенной форме, необходимо заключить его в кавычки и перед каждым словом поставить восклицательный знак. Таким образом нужно вписать в поисковую строку «!поисковая!система» .

Как видите, всего 3705 показов в месяц.
Для того, чтобы узнать, сколько раз данный вопрос задавали Google переходим по адресу https://adwords.google.com . Здесь все точно также вводит ключевое слово и нажимаем «Поиск».
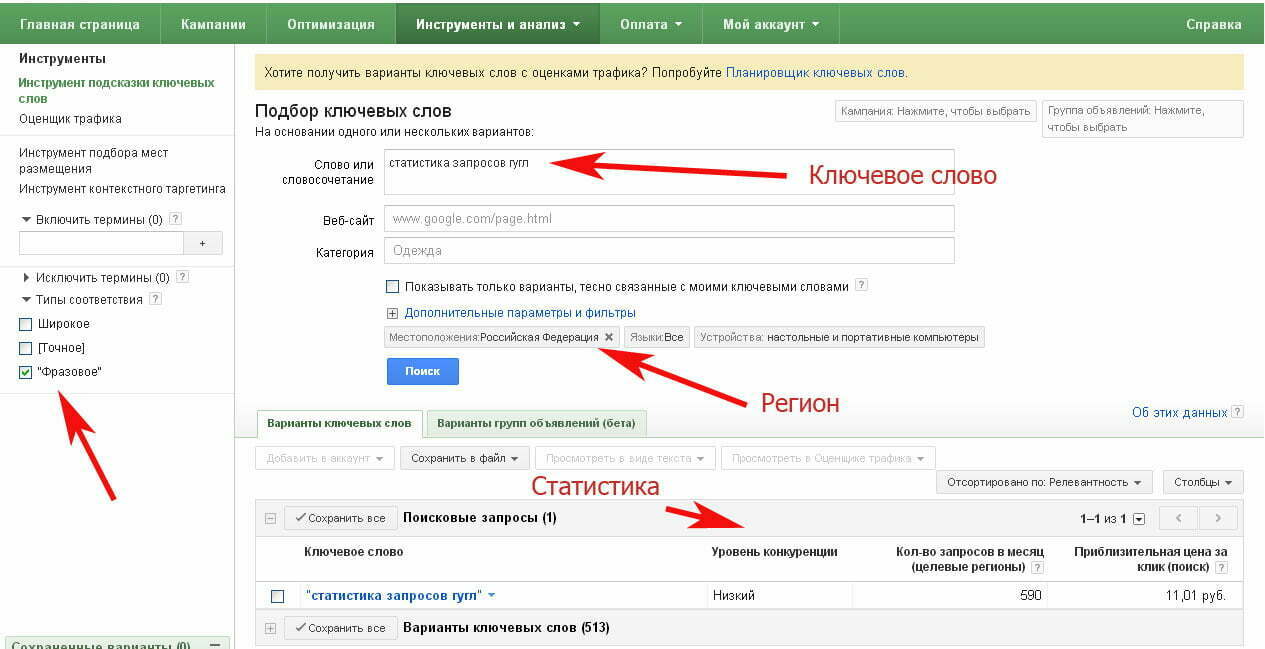
Единственное отличие состоит в том, что для того, чтобы найти частотсность ключевого слова в определенной форме необходимо поставить галочку в разделе «Типы соответствия» напротив «фразовое.
Классификация поисковых запросов по частотности
Среди оптимизаторов принято все запросы делить не три категории в зависимости от их частотности. Это «низкочастотные», «среднечастотные» и «высокочастотные», сокрощенно НЧ, СЧ и ВЧ .
- Высокочастотные запросы - ВЧ, это слова или фразы, которые чаще всего запрашиваются в данной тематике, так сказать самые популярные. Принято считать все запросы с частотностью от 10 000 и выше высокочастотными. Как правило, это однословные запросы по типу «телевизор» или «автомобиль» и т.д.
- Среднечастотный запрос - СЧ, это запросы с частотностью от 1000 до 10 000. Обычно это многословные запросы, более конкретные чем ВЧ, например «купить телевизор»
- Низкочастотные запросы – НЧ, это запросы с частотностью до 1000. Это самый конкретный тип запросов вида: «купить телевизор LG в Москве».
Ну вот и все, что я хотел сегодня Вам рассказать. Кстати, недавно наткнулся в интернете на одну хорошую фирму, которая предоставляет услуги аренды и размещения серверов. Если кого-то заинтересовало, вот ссылка http://www.di-net.ru/collocation/colocation/ . Цены на их услуги мне понравились.
Во время обучения новичков SEO, столкнулся с проблемой скудной или пере-избыточной информацией по вопросу создания Семантического Ядра для сайта. Решил сам написать краткое руководство, но так как информации всё же для одной статьи оказалось чересчур, разбил на несколько частей. В этой статье стандартная информация по использованию сервиса Яндекс.Wordstat, которая в будущем поможет разобраться со всеми премудростями составления СЯ.
Знакомимся с Яндекс.Вордстат
Для начала заходим на страницу wordstat Яндекса . Поиск будет идти по «Словам», но вначале нам нужно указать «Регион».Для примера выбираем регион «Москва» и вводим в поле Вордстата ключ «ремонт ноутбуков». Перед нами появится следующая картина:

Как видим, есть две колонки — левая и правая. Рассмотрим каждую из них более детально.
В левой колонке отображены все ключевые слова и фразы, которые содержат слова «ремонт» + «ноутбук». Здесь мы найдём следующие варианты:
- «ремонт»+»ноутбук»+»X»
- «Х»+»ремонт»+»ноутбук»
- «Х»+»ремонт»+»ноутбук»+»Х»
- «Х»+»ремонт»+»Х»+»ноутбук»+»Х»
- «Х»+»ноутбук»+»Х»+»ремонт»+»Х»
- и т.д
— где X — любое слово или словосочетание,
Так же сюда войдут и словоформы с нашим ключом. Например «ремонту ноутбуков», «ремонту ноутбука» Все рассмотренные выше фразы называются разбавленными. В реальности именно они играют ключевую роль в привлечении потенциальных клиентов.
Как видно со скрина, фразу «ремонт ноутбуков» запрашивали 21590 человек за последний месяц. Но тут есть подвох. На самом деле эта цифра показывает общее число запросов со словами «ремонт» и «ноутбук». То есть сюда вошли все те разбавленные фразы, которые Wordstat показывает ниже: «ремонт ноутбуков в Москве», «адреса ремонта ноутбуков» и др. Этот момент нужно обязательно учитывать в прогнозе численности аудитории. О том, как определять точную численность запросов и их качество я расскажу позже. Когда все возможные запросы из этой колонки собраны, переходим на правую сторону.
В правой колонке выводятся похожие запросы, которые искали пользователи. Благодаря этим данным есть возможность получить подсказку для увеличения списка ключевых слов. В данном случае видим, что есть потенциально интересные запросы вида «замена экрана ноутбука», «ноутбук сервис», «ноутбук центр» и т.д. В свою очередь, практически под каждый такой ключ можно подобрать соответствующий ему список разбавленных запросов и снова найти подходящие ключи справа. И так до тех пор, пока новые ключевые слова в Wordstat не закончатся.
Таким образом, с помощью сервиса «подбор слов» от Яндекс, можно насобирать всевозможные ключевые фразы. Естественно, для сбора ключевых слов для сайтов популярных тематик, лучше будет прибегнуть к помощи специальных программ и сервисов, которые автоматизируют процесс работы. Хочу написать про одну из таких программ немного позже. Теперь рассмотрим некоторые полезности, которые могут пригодиться.
Вспомогательные операторы Яндекс Вордстат
Подбор ключевых слов Яндекса умеет работать с определёнными символами, которые отвечают за уточнения, сортировку, группировку и т.д. Умение использовать эти операторы сильно облегчает жизнь SEOшнику.
Операторы «!» — восклицательный знак и «» — кавычки
Оператор «» кавычки используется для отсеивания разбавленных ключевых слов. Если мы применим его к ключевой фразе, Вордстат покажет только результаты именно для этой фразы с её словоформами, без учета дополнительных слов в ключах. Например: «ремонту ноутбуков», «ноутбуки ремонт», «ремонта ноутбука» и т.п.
Ещё один полезный оператор при подборе ключевых слов — знак восклицания «!». Он убирает словоформы ключевых слов. Например:

Помните я говорил выше, что цифры напротив слов ремонт ноутбуков (21590) — показывают общее число запросов со словами «ремонт» и «ноутбук». Так вот, если ключевую фразу заключить в оператор «» (кавычки) и перед началом каждого из слов без пробела поставить «!» (знак восклицания) , то мы увидим точное количество запросов по этому ключу — 2152 запроса

Разница между общим числом запросов и точным — определяет качество ключевого слова. Чем она меньше — тем качественнее ключевое слово для продвижения. Нужно обязательно помнить и уметь пользоваться этой парой операторов.
Оператор «-» минус
Применяется для исключения минус-слов. В нашем примере для сайта по ремонту ноутбуков, такими словами будут: «своими руками», «бесплатно», «смотреть», «руководство» и подобные. Например, исключим поиск по слову «Москва». Вот как выглядит обычная выдача:

Вот так выглядит выдача с минус-словом «Москва»:

Оператор «+» плюс
Используется для обязательного включения в состав ключевой фразы предлогов и союзов. Например, выведем все фразы по ремонту ноутбуков с предлогов «в» и названием города «Москва»

Перечисленных операторов для Wordstat более чем достаточно для уверенной работы с сервисом по подбору ключевых слов. Для особо извращённой аудитории, есть игрушки по-интересней.
Оператор группировки () — скобочки и оператор ИЛИ «|»
Допустим, рассматриваемые сервис занимается не только ноутбуками, но компьютерами, планшетами и пр. Кроме ремонта выполняются и другие действия: диагностика, чистка и пр. Чтобы не вводить все эти известные запросы каждый раз по новой, мы можем сгруппировать их и записать в виде одного запроса. В данном случае это будет выглядеть так:

Теперь переходим к реальным извращениям. На предыдущем скрине мне не понравилось. что в списке есть минус-слова и для большей точности захотелось вывести ключи с точным словом «Москве» и с предлогом «в». Используя все описанные выше операторы, я составил следующий запрос:

Единственный момент, который стоит помнить — операторы не работаю при поиске по региону и истории запросов

PS. Подписывайтесь на обновления нашего блога. Сейчас все силы направлены на запуск WP-Puzzle , проработку партнёрки для наших читателей, составление описаний плагинов и т.д. Но уже скоро всё будет 🙂 Стараемся не пропадать и всегда отвечать на ваши вопросы в комментариях.

 Легенды поселения кокошкино Поселение кокошкино
Легенды поселения кокошкино Поселение кокошкино Что приготовить из морского коктейля: рецепты
Что приготовить из морского коктейля: рецепты Интересные факты о ярославе мудром
Интересные факты о ярославе мудром Технологическая карта урока истории «Древний мир – рождение первых цивилизаций Урок древний мир рождение первых цивилизаций
Технологическая карта урока истории «Древний мир – рождение первых цивилизаций Урок древний мир рождение первых цивилизаций